Problem
Frontier-scale foundational AI models have driven a rapid expansion in both the size and deployment speed of training clusters. A single training run can now span more than one hundred thousand GPUs. Data centers supporting these clusters are projected to more than triple global electricity consumption by 2028 (DOE 2024).
Modern AI training distributes computation across thousands of GPUs that must periodically synchronize, producing concurrent power spikes and dips across entire racks causing:
•Destabilized local electrical grids, brownouts/blackouts
•Power delivery inefficiency and increase stress on upstream hardware (DC/DC, AC/DC)
•Negative performance and reliability in production datacenters
Existing mitigation strategies rely on costly energy buffering at every power conversion step, introducing inefficiency, latency, and reliability risks. This calls for a proactive and scalable solution to ensure stable power delivery. Proactively managing their power profiles will help prevent widespread outages and climate-related risks, while enabling sustainable AI growth.
The Solution
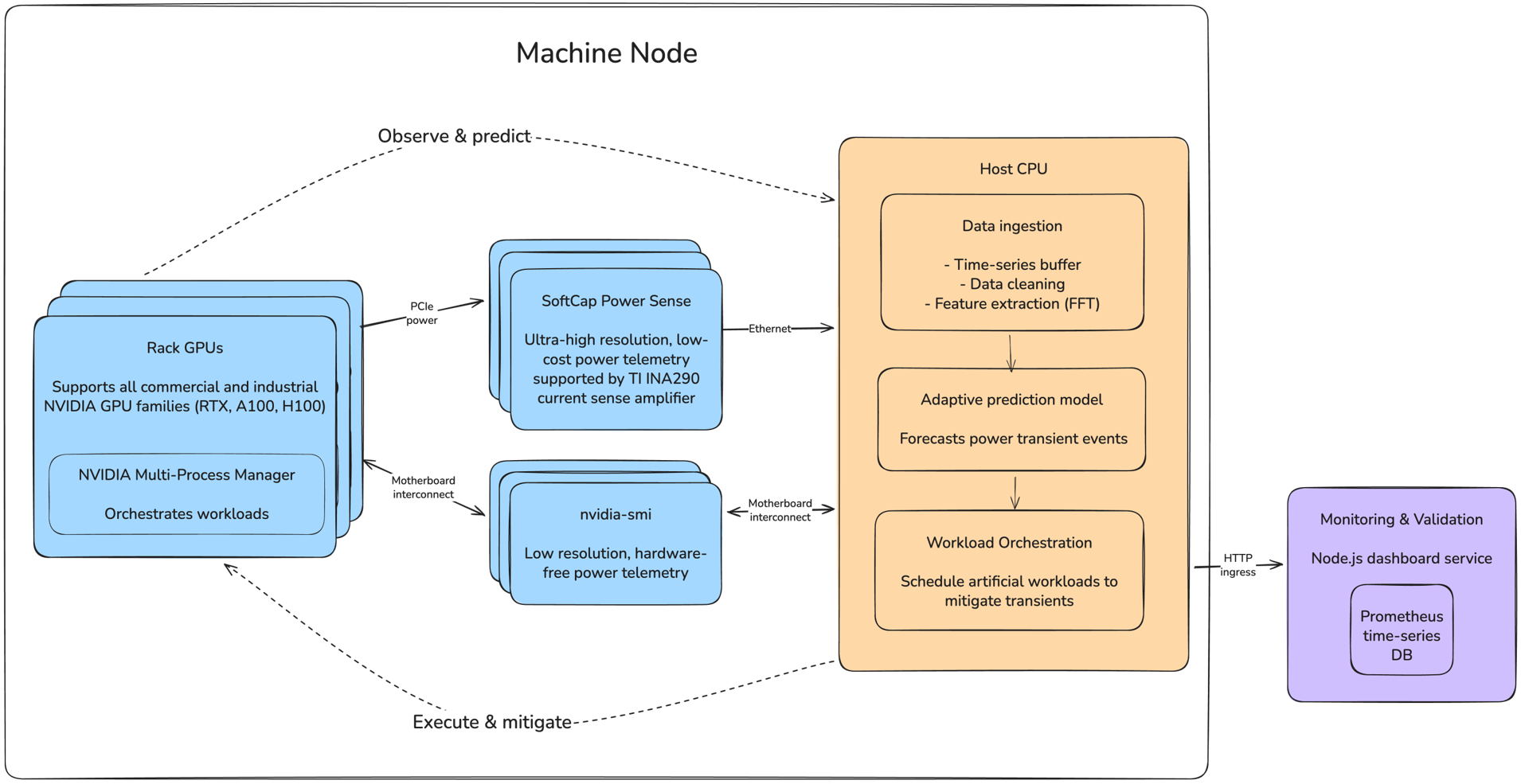
1.Data telemetry
Time-domain power data streaming via custom shunt PCB or nvidia-smi
2.Transient prediction
Autocorrelation-based period detection with adaptive template learning to forecast power trajectories P(t + Δt), ramp rates dP/dt, and phase flags
3.Transient mitigation
NVIDIA MPS-enabled scheduler that injects secondary workloads or staggers training jobs to flatten rack-level power curves
4.Monitoring UI
Real-time dashboard displaying per-GPU power draw, forecast windows, and scheduling states
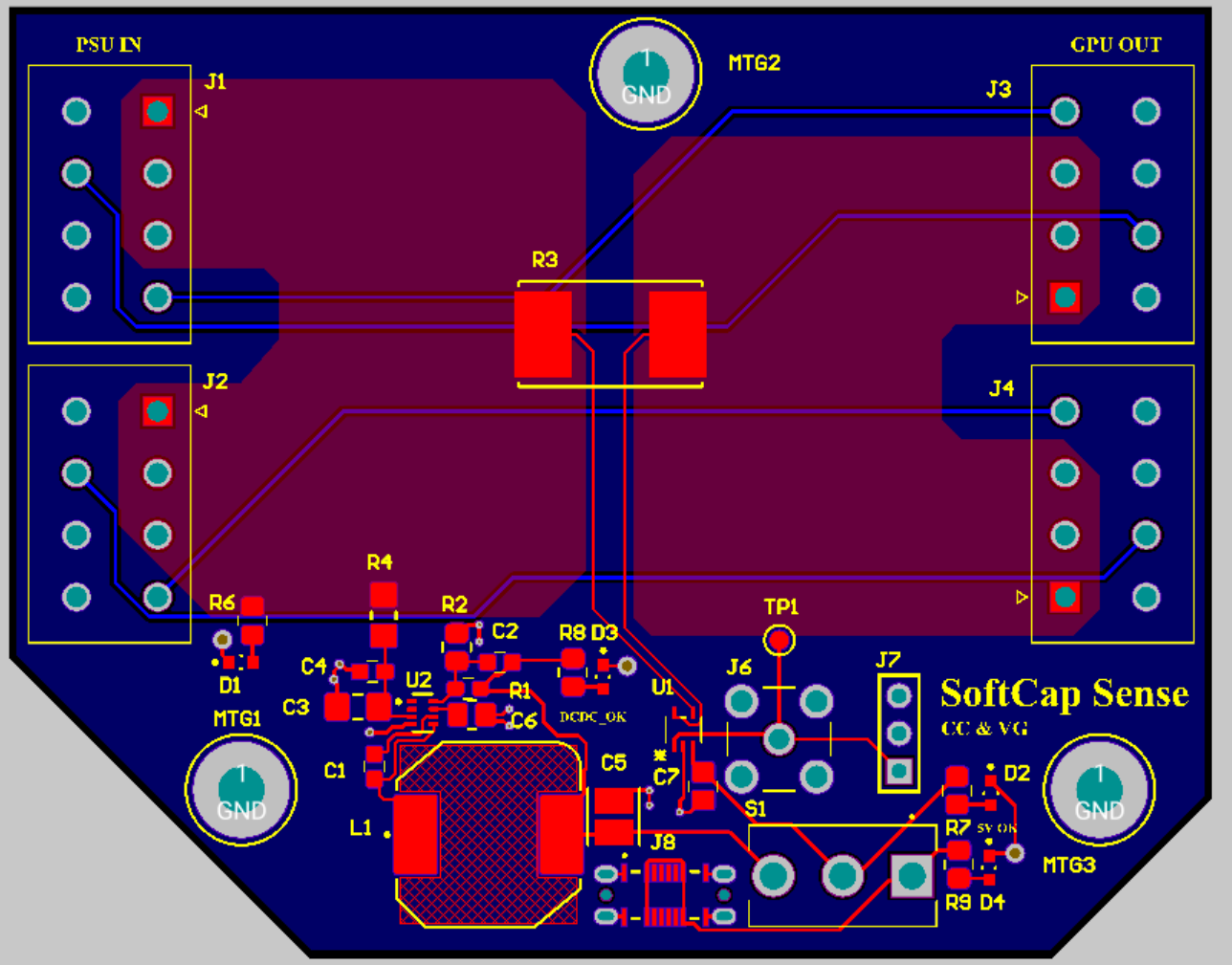
Supporting Hardware
Features
•High-resolution power telemetry at 10 kHz sampling rate (100× faster than NVIDIA-SMI's 100ms polling)
•Minimal parasitic effect via shunt-based current sensing, scalable to 8+ GPUs per rack with straightforward deployment
•Measurable reduction in rack-level di/dt transients and harmonic content